Крупномасштабные модели искусственного интеллекта
Что могут делать большие модели искусственного интеллекта (ИИ)? Крупномасштабные языковые модели ИИ могут генерировать статьи, неотличимые от статей, написанных людьми, и помогать разработчикам программного обеспечения завершать коды программ. К примеру, несмотря на то, что читатель не знаком с древними китайскими языками, он может просматривать изображения, сгенерированные моделью ИИ, которые создают изображения на базе древних китайских стихов династии Тан. Более того, модели ИИ теперь могут генерировать серии изображений из последовательности текстовых описаний, чтобы рассказывать истории. Крупномасштабные модели ИИ открывают новые возможности для таких начинаний. В этой статье обобщаются рост рынка крупномасштабных моделей ИИ, потенциал, который они предлагают, и их требования.
Введение
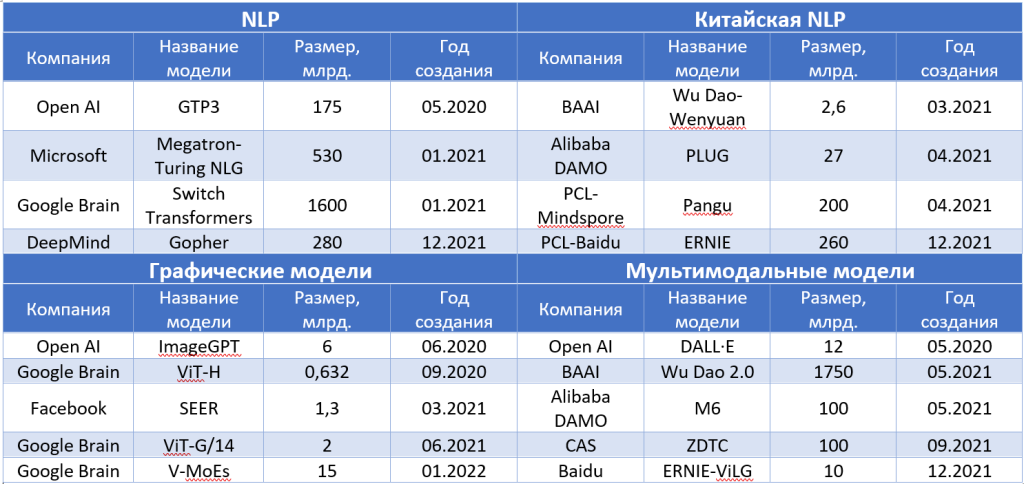
Давайте задумаемся о ключевой вехе в авторитетной истории языковых моделей, основанных на глубоком обучении. Generative Pretrained Transformer 3 (GPT-3), разработанный OpenAI в 2020 году, представляет собой модель обработки естественного языка (NLP — natural language processing). GPT-3 добился ошеломляющего прорыва, выпуская статьи, краткие содержания книг, выполнял автозаполнение программных кодов и так далее. Хотя предшественник GPT-3, GPT-2, имеет всего около 1,5 миллиарда параметров и обучается почти на 40 ГБ текстовых данных, GPT-3 имеет примерно 175 миллиардов параметров и обучается почти на 45 ТБ текстовых данных. Таким образом, GPT-3 впечатляет не только своими возможностями, но и размером. Значительное увеличение размера модели с GPT-2 до GPT-3 отражает тенденцию к созданию крупномасштабных моделей ИИ.
Крупномасштабные одномодальные модели
С момента выпуска GPT-3 создание более крупных моделей для достижения превосходной производительности или решения более сложных задач стало тенденцией. Полученные модели часто считаются крупномасштабными моделями ИИ, хотя строгого определения нет. Например, DeepMind выпустила модель NLP Gopher с 280 миллиардами параметров. Microsoft запустила модель Megatron-Turing Natural Language Generation, которая имеет 530 миллиардов параметров. В настоящее время разрабатываются еще более крупномасштабные языковые модели, в том числе Switch Transformer, в результате чего получается модель NLP с 1,6 триллионами параметров. Ключевым компонентом структуры Switch Transformer является смешение экспертов (MoE), которое объединяет несколько экспертных сетей параллельно и играет центральную роль в увеличении размера модели. По сравнению со сложностью человеческого мозга, который имеет около 100 триллионов параметров, похоже, еще есть место для увеличения размера модели.
Точно так же быстро растут размеры китайских моделей NLP. Хотя китайский язык сильно отличается от английского, особенно если учесть различные сегментации слов, китайские модели NLP также обеспечивают превосходную производительность за счет гипермасштабируемых моделей. Wu Dao-Wen Yuan, разработанная Пекинской академией искусственного интеллекта (BAAI) как компонент Wu Dao 1.0 (набор сверхмасштабных моделей, ориентированных на китайский язык), является одной из первых китайских моделей NLP и имеет 2,6 миллиарда параметров. Другие крупные китайские компании продолжают анонсировать свои собственные гипермасштабные китайские модели NLP. В апреле 2021 года исследовательская группа Alibaba Discovery, Adventure, Momentum and Outlook (DAMO) представила китайскую модель NLP Pretraining for Language Understanding and Generation (PLUG), которая имеет 27 миллиардов параметров. Размер модели PLUG в 10 раз больше, чем у Wu Dao-Wen Yuan. Через несколько недель была запущена другая китайская модель NLP, Pangu, с 200 миллиардами параметров. Эти китайские модели NLP могут решать языковые задачи, такие как обобщение текста, ответы на вопросы и создание диалогов. Более того, могут создавать стихи и двустишия в древнекитайском стиле. В конце 2021 года Peng Cheng Laboratory и Baidu анонсировали модель NLP Enhanced Representation Through Knowledge Integration (ERNIE), которая имеет 260 миллиардов параметров. ERNIE был развернут как часть облачных сервисов Baidu и может обрабатывать документы на китайском языке, такие как финансовые контракты.
Хотя методы глубокого обучения изначально были заимствованы из компьютерного зрения для решения задач NLP, исследователи начали применять методы NLP для реализации задач компьютерного зрения. Тенденция крупномасштабных моделей в области NLP распространяется на область компьютерного зрения. Модель Vision Transformer (ViT)-H, использующая архитектуру трансформатора для задач компьютерного зрения, изначально имела всего 632 миллиона параметров. Улучшенная версия Scaling ViTs увеличила размер модели до 2 миллиардов параметров. Ученые также исследовали перенос успеха самоконтролируемого обучения в NLP на компьютерное зрение. Результатом стали крупномасштабные модели машинного зрения Self-Supervised (SEER) и Image GPT с 1,3 и 6 миллиардами параметров соответственно. Вслед за ViT архитектура технического зрения на основе разреженного MoE (V-MoE) представляет собой новый тип архитектуры, подходящий для параллельной обработки. Модель экземпляра, использующая архитектуру V-MoE с 15 миллиардами параметров, показала точность теста на ImageNet 90,35 %, что близко к современному уровню развития техники (оптимальная максимальная точность составляет 90,88 % на момент написания статьи1).
Теоремы универсальной аппроксимации дают некоторые подсказки относительно того, почему размер моделей ИИ имеет решающее значение, предполагая, что нейронная сеть может аппроксимировать любую непрерывную функцию. Во-первых, версия универсальных теорем аппроксимации произвольной ширины утверждает, что нейронная сеть, по крайней мере, с одним скрытым слоем может аппроксимировать любую непрерывную функцию.2 Одна из первоначальных версий универсальных теорем аппроксимации была доказана для нейронных сетей с сигмоидальными функциями активации и позже включила более широкий класс функций активации. Во-вторых, для сверточных нейронных сетей была успешно доказана версия универсальных теорем аппроксимации произвольной глубины, в которой нейронные сети имеют ограниченную ширину. Эти теоремы утверждают, что если модель достаточно глубокая или широкая, ее можно обучить выполнить обозначенную задачу, аппроксимируя непрерывную функцию. Однако мало что известно о разработке эффективных и действенных алгоритмов обучения для поиска нейронной сети для поставленной задачи.
Крупномасштабные мультимодальные модели
Объединение модальностей естественного языка и изображений — это новая стратегия, используемая для улучшения возможностей моделей ИИ таким же образом, как люди учатся, читая и видя. Модели, использующие такую стратегию, классифицируются как мультимодальные модели машинного обучения; они могут использовать несколько модальностей, таких как изображения, видео, текст и аудио. Примером мультимодальной модели является сеть Contrastive Language-Image Pretraining network, разработанная OpenAI для сопоставления пар изображений и текста в задачах классификации изображений. Мультимодальные модели предназначены для обработки мультимодальных задач, таких как создание подписей к изображениям и межмодальный поиск. Мультимодальное машинное обучение стремится отображать мультимодальную информацию в единое пространство представления, аппроксимируя назначенную задачу как функцию в этом пространстве и отображая результат из этого пространства обратно в целевую модальность. Это все еще активная область для поиска подходящего пространства представления или скоординированности из-за различий между несколькими модальностями, такими как распределение данных и уровни шума. В дополнение к обучению с учителем, подход к обучению без учителя играет ключевую роль для мультимодальных задач. Например, генеративные модели, которые являются своего рода методами обучения без учителя и фиксируют совместное распределение вероятностей наблюдаемых и целевых переменных, могут аппроксимировать совместное распределение вероятностей текстов и изображений для создания изображений из текстов. машинного обучения, в некоторых недавних работах началось теоретическое обсуждение того, когда и почему мультимодальное обучение может превзойти одномодальное обучение6.
Расширение размеров гипермасштабируемых моделей открывает прекрасную возможность для роста мультимодальных моделей. На рис. 1 представлен пример изображений, сгенерированных из текстового описания на английском языке. Вскоре после введения GPT-3 была представлена DALL·E, мультимодальная модель на основе GPT-3, используемая для создания изображений из заданной текстовой подписи и названная так по имени художника Сальвадора Дали и робота WALL·E от Pixar. DALL·E использует версию GPT-3 с 12 миллиардами параметров и может выполнять мультимодальные задачи, такие как преобразование изображения в изображение, одежду и дизайн интерьера. Alibaba DAMO анонсировала свою мультимодальную модель Multi-Modality to Multi-Modality Multitask Megatransformer (M6), размер которой составляет 100 миллиардов параметров. M6 использовался для предоставления нескольких услуг, таких как кросс-модальный поиск и дизайн одежды с помощью ИИ. BAAI представила Wu Dao 2.0 (с его 1,75 триллионами параметров) — преемницу Wu Dao 1.0 — как мультимодальную модель, которая может обрабатывать как английский, так и китайский текст и изображения (а именно, двуязычные и бимодальные модели). Wu Dao 2.0 может генерировать стихи, написанные в древнекитайском стиле, отвечать на вопросы, писать эссе и снабжать изображения подписями. Zi Dong Tai Chu (ZDTC) выходит за рамки простой комбинации модальностей текста и изображения и представляет собой первую модель, сочетающую три модальности: естественный язык, изображения и звук. Модель ZDTC была запущена Китайской академией наук (CAS). Обладая 100 миллиардами параметров, ZDTC может выполнять мультимодальные задачи, такие как создание изображений из аудио и воспроизведение звука из изображений.

Рисунок 1. Изображение, созданное DALL·E из текстового описания, предоставленного Ramesh et al. 5
В таблице 1 приведены некоторые недавние крупномасштабные модели, посвященные таким темам, как NLP, NLP на китайском языке, видение и мультимодальные модели. Из-за размеров гипермасштабных моделей эти модели, скорее всего, развертываются в облачных средах и предоставляются в виде облачных сервисов.
Масштабное обучение — краеугольный камень крупномасштабных моделей ИИ
Старший научный сотрудник и старший вице-президент Google Research Джефф Дин предсказал, что более крупные и функциональные модели машинного обучения являются одной из пяти важных тенденций7 , которые уже были продемонстрированы крупномасштабными моделями. Еще одна ожидаемая тенденция — повышение эффективности крупномасштабного машинного обучения. Поскольку обучение крупномасштабных моделей ИИ требует чрезвычайно больших вычислительных ресурсов, исследователи и инженеры из разных областей сотрудничают для повышения эффективности. Ниже приведены некоторые предлагаемые стратегии:
- Аппаратное ускорение: в дополнение к ЦП и ГП были разработаны специализированные аппаратные ускорители, такие как тензорные и нейросетевые процессоры для обучения ИИ и логических выводов на уровне микросхемы, которые позволили повысить эффективность.
- Крупномасштабный параллелизм. Крупномасштабный параллелизм включает типы данных, модели и конвейера. Разнородные вычислительные узлы интегрированы и скоординированы таким образом, что все узлы беспрепятственно взаимодействуют при выполнении заданной учебной задачи, уменьшая задержки внутриузловой и межузловой связи и правильно распределяя и объединяя вычисления в различных архитектурах моделей.
- Интеграция проектов. Использование инновационных параллельных проектов в средах машинного обучения имеет решающее значение для облегчения обучения крупномасштабных моделей с помощью специализированных распределенных вычислительных платформ. Например, Switch Transformer обучался с использованием специального программного стека под названием Mesh Tensorflow, распределенной среды глубокого обучения, а Wu Dao 2.0 обучался с использованием FastMoE8, распределенной системы обучения, реализованной на основе PyTorch (распространенной среды глубокого обучения).
- Эффективная архитектура модели. Архитектура модели, эффективная для обучения, может быть разработана для увеличения размера модели для более сложных или обобщенных задач. Например, Switch Transformer был разработан с использованием архитектуры MoEs, чьи вычислительные затраты остаются почти неизменными, даже при увеличении количества параметров.9
Крупномасштабные модели как предварительно обученные модели.
Целью обучения крупномасштабных моделей является получение обобщенной модели, способной решать несколько схожих задач. Таким образом, разработчики надеются приблизиться к разработке общего искусственного интеллекта, который может учиться и решать проблемы, как это делают люди. Кроме того, поскольку стоимость обучения крупномасштабной модели значительна, поддержка нескольких одинаковых задач существенно снижает накладные расходы. На концепцию использования моделей для решения нескольких похожих задач ссылаются связанные термины, такие как предварительно обученные модели, базовые модели и трансферное обучение. Рисунок 2 абстрактно визуализирует эту концепцию.
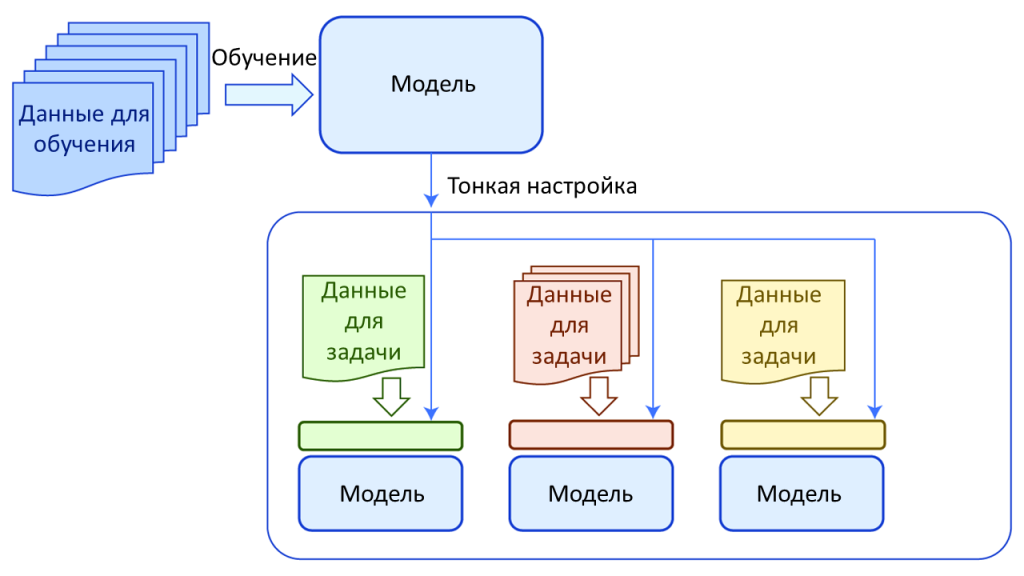
Рисунок 2. Высокоуровневое представление процессов предварительной подготовки и тонкой настройки.
Модель сначала обучается для выполнения общей задачи с использованием начального набора обучающих данных посредством процесса, называемого предварительной подготовкой. Полученная модель позже переобучается для другой конкретной задачи с использованием другого набора обучающих данных для конкретной задачи, который обычно намного меньше исходного набора обучающих данных. Эти конкретные задачи называются последующими задачами, а процесс переобучения называется тонкой настройкой. Затем знания исходной модели используются для более конкретной задачи. Поэтому этот процесс называется трансферным обучением. Он вдохновлен идеей, что ранее полученные знания могут быть использованы для решения новых проблем. Таким образом, исходная модель называется базовой или предварительно обученной моделью. Принятие предварительно обученных моделей в качестве основных компонентов (вместо разработки совершенно новых моделей) для последующих задач является нормой.
Вышеупомянутые крупномасштабные модели могут функционировать в качестве базовых моделей. Например, GPT-3 не только генерирует естественный язык и создает письменные статьи, но также выполняет последующие задачи, такие как создание программного кода и вывод структурированных данных.
Гипермасштабный размер эффективен для повышения производительности модели в одномодальных и мультимодальных задачах; это также шаг к развитию общего искусственного интеллекта. Крупномасштабные модели предъявляют чрезвычайно высокие вычислительные требования. Передовые методы совместного проектирования аппаратного и программного обеспечения постоянно разрабатываются для поддержки крупномасштабных моделей следующего поколения. Тенденция к увеличению размера модели ИИ, похоже, не прекращается. Тем не менее, только несколько крупных компаний и ведущих институтов могут идти в ногу с этой тенденцией, потому что входные барьеры значительны. Поэтому желательны альтернативные методы улучшения производительности модели. В некоторых исследованиях изучались методы, отличные от увеличения размера модели, для достижения превосходной производительности в конкретных и общих задачах. Увеличение размера модели не является конечной целью; это только одно из различных средств улучшения производительности модели.
Источники:
H. Lin, «Large-Scale Artificial Intelligence Models» in Computer, vol. 55, no. 05, pp. 76-80, 2022.
doi: 10.1109/MC.2022.3151419
Abstract: As artificial intelligence models rapidly grow in size, their potential is stimulated.
url: https://doi.ieeecomputersociety.org/10.1109/MC.2022.3151419