
Неофициальный перевод, только для ознакомления.
Автор: Пэн Чжао (основатель ZhiNext, соучредитель фонда Cloud and Capital Partners)
Дата: 9 апреля 2025 года
Это моя 367-я колонка.
В нескольких предыдущих статьях я подробно обсуждал тенденции развития интеллекта на границе сети (Edge Intelligence).
Сегодня локальный ИИ (Edge AI) и периферийный интеллект стали центральными темами в отрасли — от технологических гигантов до инновационных стартапов все стремятся занять позиции в этой новой области. NVIDIA, OpenAI, Google, Amazon и другие лидеры отрасли активно инвестируют в Edge AI, чтобы захватить лидерство.
Маркетинговые исследования подтверждают огромные перспективы Edge AI.
Согласно прогнозам из «Полного руководства по периферийному ИИ: Справочник по трансформации бизнеса с помощью периферийного ИИ», мировой рынок Edge AI вырастет с 19 миллиардов долларов в 2023 году до 163 миллиардов долларов к 2033 году. Недавнее исследование IDC среди 27 отраслей показало, что расходы на решения для граничных вычислений достигнут почти 261 миллиарда долларов в 2025 году и будут расти с годовым темпом 13,8%, достигнув более 380 миллиардов долларов к 2028 году.
Известная исследовательская компания Gartner также дает поразительные прогнозы: к 2025 году более 50% данных управления предприятиями будут создаваться и обрабатываться вне центров обработки данных или облака.

К 2026 году как минимум половина развертываний граничных вычислений будет обладать возможностями машинного обучения, тогда как в 2022 году этот показатель составлял всего 5%.

Развитие интеллектуальных технологий не только привело к технологическим изменениям, таким как снижение вычислительной мощности и принятие решений в режиме реального времени, но и породило новое направление в области искусственного интеллекта: вертикальные большие модели.
Традиционным большим моделям общего назначения часто сложно найти баланс между эффективностью и точностью, когда они сталкиваются со сложными и меняющимися требованиями отрасли. Чтобы модели ИИ могли лучше понимать отраслевые знания и решать проблемы в конкретных областях, были созданы специализированные большие модели для вертикальных отраслей.
Поэтому в данной статье будет проведен углубленный анализ тенденций развития вертикальных моделей в сфере AIoT. Мы рассмотрим следующие основные вопросы: Почему AIoT особенно нуждается в вертикальной модели? Каким образом ИИ-технологии и вертикальные модели могут обеспечить взаимное продвижение и беспроигрышные результаты? Каковы возможности и проблемы внедрения вертикальных моделей в AIoT?
«Сценарий — король, модель — инструмент»: неизбежный рост вертикальных моделей
Сегодня, когда во всем мире популярны общие большие модели, нам следует также спокойно изучить их ограничения в сценариях AIoT. Общие большие модели не всесильны, особенно в таких областях, как AIoT, которые тесно связаны с физическим миром; они сталкиваются с дилеммой «физических слепых зон».
Хотя общие большие модели продемонстрировали выдающиеся возможности в генерации текста, понимании изображений и взаимодействии человека с компьютером, эти возможности в большей степени вытекают из «статистических рассуждений о больших данных», а не из глубокого понимания реального физического мира.
Данные в области AIoT имеют свои уникальные характеристики: большой объем данных поступает от датчиков, машин и оборудования, а также от переменных окружающей среды. Его основными характеристиками являются временные ряды, неструктурированность, работа в режиме реального времени и наличие шумовых помех.
Общим большим моделям часто сложно эффективно обрабатывать данные таких сложных структур, и они не способны моделировать физические законы, состояние оборудования и контекст окружающей среды. Эксперимент показал, что при обработке необработанных данных датчиков GPT-4 точность распознавания активности составляла всего 40%, а точность диагностики машины — всего 50%, что намного ниже приемлемых отраслевых стандартов.
Этот результат выявляет ключевую проблему: в общей модели отсутствуют не только параметры, но и знание сцены и физическая логика.
По мере того, как ИИ переходит от зрелищности к практичности и от удобства использования к управляемости, требования AIoT к интеллекту меняются от «общих» к «вертикальным». Таким образом, вертикальные большие модели стали неизбежным путем для ИИ на пути от «общего интеллекта» к «сценарному интеллекту».
Что такое вертикальная макромодель?
Это относится к большой системе моделей, которая предварительно глубоко обучена и настроена с использованием данных предметной области и опыта в конкретной отрасли или сценарии. По сравнению с обычными моделями вертикальные большие модели имеют три существенные характеристики:
- Специализация в отрасли: ориентация на определенную вертикальную отрасль (например, производство, энергетика, логистика, парки, медицинское обслуживание и т. д.)
- Внедрение знаний: интеграция отраслевого графика знаний, системы правил и профессиональной терминологии.
- Оптимизация производительности: более высокая точность и меньшее потребление ресурсов при выполнении определенных задач
В целом вертикальные большие модели имеют следующие три преимущества:
Прежде всего, они разработаны для конкретных отраслей и сценариев, могут понимать отраслевой язык и бизнес-процессы, а также обладают способностью «понимать сценарии». Например, на умном заводе вертикальные модели могут не только выявлять аномалии в работе оборудования, но и делать выводы о возможных отклонениях в процессе.
Во-вторых, поскольку данные для обучения более сфокусированы, а структура модели более оптимизирована, вертикальные модели работают более стабильно при выполнении ключевых задач (таких как предиктивное обслуживание, планирование энергопотребления и идентификация состояний), а также являются более интерпретируемыми и контролируемыми, что способствует соблюдению корпоративных требований и принятию решений.
Наконец, вертикальные модели обычно обладают лучшими возможностями сжатия моделей и эффективностью рассуждений и могут быть развернуты на периферии для реализации локальных вычислений, отвечая строгим требованиям AIoT к работе в режиме реального времени, низкой задержке и автономной работе.
Почему AIoT особенно нуждается в вертикальных моделях?
Основная причина в том, что AIoT — это не единый сценарий, а пересекающееся слияние тысяч отраслей. Его интеллектуальный путь модернизации по сути представляет собой скачок от «интеллекта устройства» к «интеллекту сцены», и ключевой опорой этого скачка является вертикальная большая модель.
- Данные AIoT специфичны для отрасли, и модель также должна быть специфичной для отрасли;
- Решения AIoT принимаются на основе сценариев, и модель также должна понимать логику сценария;
- Развитие AIoT происходит на периферии, и модель также должна иметь возможность работать «вниз».
В этом контексте общая большая модель подобна универсальному ключу, но на самом деле она не может открыть эти «отраслевые двери»; а вертикальная модель — это специально созданный «специальный ключ», который действительно способен проникать в сценарии и реализовывать бизнес.
Суть AIoT «ориентирована на сценарий», а вертикальные модели — это «ноги», которые по-настоящему внедряют ИИ в тысячи отраслей. Только двигаясь от общего к вертикальному, искусственный интеллект вещей может достичь долгосрочного развития.
От «общего» к «специализированному», от периферийного интеллекта к интеллектуальной периферии
Быстрое развитие периферийного интеллекта заставляет модели ИИ «опускаться» к периферийным устройствам, а вертикальные модели больше подходят для эффективной работы в периферийных средах с ограниченными ресурсами.
Периферийный ИИ и вертикальные большие модели в сфере AIoT не являются строго «взаимоотношениями спереди и сзади», а представляют собой «взаимно движущие и спиральные» отношения.
В практической реализации наблюдается тенденция к переходу на передовые технологии, за которыми следует углубление вертикальных больших моделей.
В частности, периферийный ИИ представляет собой оптимизацию и снижение вычислительной архитектуры, делая акцент на снижении вычислительной мощности ИИ, модельного обоснования, обработки данных и других возможностях периферийных устройств, в то время как вертикальные большие модели подчеркивают специализацию, уточнение и отраслевую специфику возможностей модели, что представляет собой углубление обучения модели и внедрение знаний. Таким образом, это два технологических развития в разных измерениях, но они взаимообусловлены.
С одной стороны, взрывной рост данных с периферийных устройств и терминалов обеспечил обилие данных частного характера в отрасли, предоставив ключевой источник данных для обучения и точной настройки крупных вертикальных моделей. Популяризация периферийного ИИ также способствовала расширению возможностей развертывания моделей, благодаря чему вертикальные модели получили реальные «контейнеры».
С другой стороны, внедрение вертикальных больших моделей повысило «уровень интеллекта» периферийных устройств, позволив им не только «воспринимать мир», но и «понимать сценарии», способствуя переходу периферийного ИИ от «восприятия» к «познанию».
С точки зрения технологической эволюции лидирующие позиции занимает передовой интеллект.
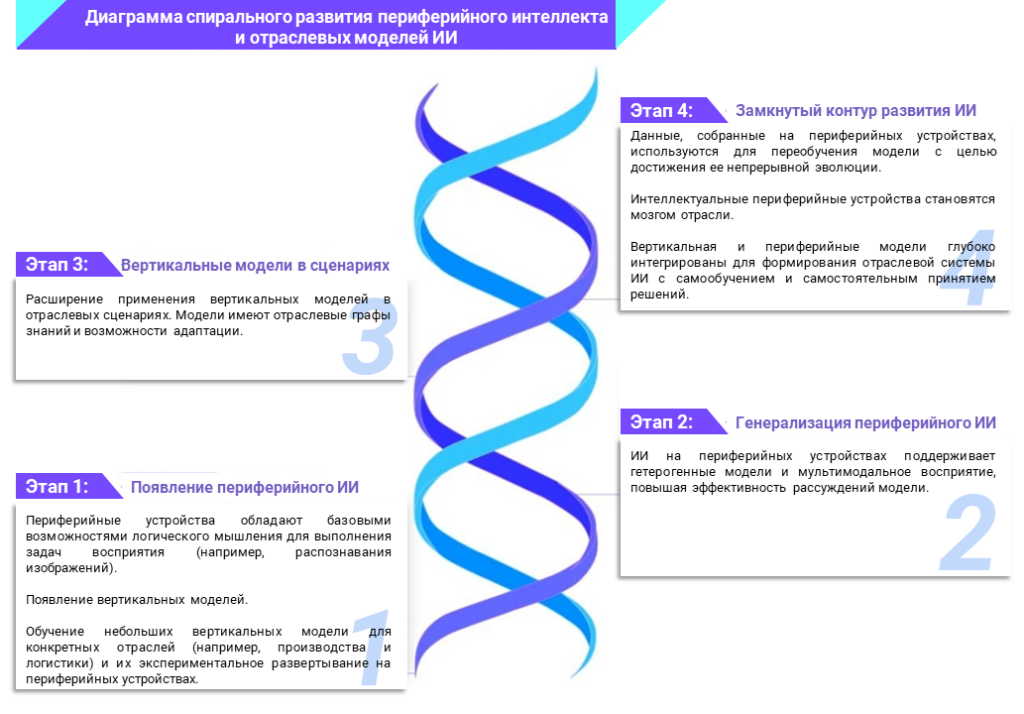
В целом, зрелость периферийного интеллекта является одним из предварительных условий для внедрения AIoT в крупные вертикальные модели, но эти два условия не находятся в строгом порядке приоритета, а скорее являются взаимообусловленными и развиваются совместно.
Передовой ИИ предоставляет «операционную платформу» и «топливо для данных» для вертикальных больших моделей. Вертикальные большие модели привносят «когнитивные способности» и «отраслевые знания» в передовой интеллект. Предприятиям следует стратегически «продвигаться на двух фронтах», сосредоточившись на модернизации периферийной инфраструктуры, с одной стороны, и вертикальном обучении и применении моделей, с другой.
В частности, интеграция периферийного интеллекта и вертикальных больших моделей в основном идет по трем путям: на основе сценариев, эволюции архитектуры и замкнутого цикла данных.
Сценарно-ориентированный подход представляет собой трансформацию от «общего интеллекта» к «сценарному интеллекту».
Основная ценность AIoT заключается в использовании ИИ для решения конкретных задач, которые часто в значительной степени основаны на сценариях. Бизнес-логика, структура данных и цели оптимизации каждой вертикальной отрасли совершенно различны, и общие большие модели не могут понять существенных различий. Только с помощью вертикальной большой модели мы можем преобразовать «отраслевой язык» в «машинный язык» и реализовать настоящий бизнес-анализ.
Типичные сценарии применения включают интеллектуальное производство, интеллектуальные города , управление энергоснабжением и т. д. Технологической тенденцией периферийного интеллекта является «обобщение технологий», но путь внедрения — «вертикальность сценария». По-настоящему ценная модель — не самая общая, а та, которая лучше всего понимает бизнес.
Архитектурная эволюция идет от интеллектуального взаимодействия «облако + конечный продукт» к «облако + периферия + конечный продукт».
По мере роста возможностей периферийных вычислений архитектура AIoT начинает претерпевать глубокие изменения. Трехуровневое взаимодействие «облако + периферия + конечная сеть» стало общепринятой моделью, в которой облако отвечает за обучение больших моделей, единое управление знаниями и выпуск политик; периферийные устройства реализуют модельное обоснование, легкую тонкую настройку и реакцию в реальном времени; а конечная цель отвечает за сбор данных, выполнение действий и обратную связь по результатам.
Крупные вертикальные модели необходимо адаптировать к этой архитектуре и улучшить их приспособляемость к локальной среде с помощью облачного обучения, удаления ненужных данных на периферии и развертывания сжатия, а также поддержки тонкой настройки небольших выборок на периферии. Периферийная аналитика — это не просто «дополнительный уровень», а «интеллектуальная передовая линия». Только когда вертикальные модели получат возможности развертывания на периферии, AIoT сможет по-настоящему реализовать принцип «что видишь, то и получаешь, что чувствуешь, то и является решением».
Замкнутый цикл данных использует данные частного домена для обеспечения непрерывной эволюции модели.
Данные в сценариях AIoT сильно децентрализованы, приватизированы и маргинализированы, что создает проблемы, но также предоставляет возможности для оптимизации модели. Сбор структурированных/неструктурированных данных на периферийных устройствах, выполнение локальных рассуждений, сравнение результатов с фактической ситуацией, вывод обратной связи об ошибках для точной настройки модели и, в конечном итоге, формирование адаптивного замкнутого цикла — это ключевой путь к оптимизации больших моделей.
Данные частного домена ближе к бизнесу, более конфиденциальны, более актуальны и имеют более высокую ценность для принятия решений. Предприятиям необходимо создать механизм замкнутого цикла данных, чтобы модель «понимала вас лучше, чем больше вы ее используете». Периферийный ИИ — это одновременно «нервные окончания» для восприятия мира и «золотая жила данных» для разумной эволюции.
Таким образом, периферийный интеллект и вертикальные большие модели являются «двумя драйверами» AIoT, а три основных пути их интеграции — основанные на сценариях, архитектуре и данных.
Вторая половина большой модели — это основа вертикальной модели.
По мере того, как крупные модели ИИ переходят от периода технологических прорывов к периоду промышленной интеграции, фокус конкуренции также незаметно смещается. Дифференцированная конкуренция в будущем будет заключаться не в том, у кого более крупные параметры модели, а в том, кто по-настоящему овладеет отраслевыми ноу-хау и создаст свой собственный «отраслевой мозг».
В эпоху AIoT 2.0 уровень интеллектуальности предприятия больше не зависит от того, «применяет ли оно ИИ », а от того, обладает ли оно способностью глубоко интегрировать «отрасль + модель». Только компании, обладающие возможностями создания вертикальных крупномасштабных моделей, могут по-настоящему внедрить ИИ в бизнес-процессы и создать стабильную, контролируемую и устойчивую интеллектуальную систему.
В последние несколько лет конкуренция за крупные модели ИИ напоминает «гонку вооружений»: чем больше параметров, тем шире корпус и выше вычислительная мощность. Однако фактическое внедрение искусственного интеллекта в тысячи отраслей промышленности говорит нам: какой бы большой ни была модель, она все равно будет бесполезна, если вы не понимаете отрасль.
Общая модель подобна энциклопедии, знающей все; вертикальная модель подобна отраслевому эксперту, знающему, что делать. В AIoT истинный ключ заключается не в том, на скольких языках может говорить модель, а в том, может ли она понимать сигналы машины, понимать логику работы завода и оценивать риски нагрузки на электросеть.
Основой конкурентоспособности в будущем станет тот, кто лучше понимает «отрасль + модель». Это свидетельствует о том, что крупные модели на этапе «ИИ+» переживают смену парадигмы от «конкуренции параметров» к «конкуренции сценариев».
Чтобы достичь интеллекта «понимания отрасли», предприятиям необходимо избавиться от заблуждения, что «общие модели являются универсальными инструментами», и выйти на этап глубокой настройки вертикальных больших моделей. Обычно включает четыре этапа:
Во-первых, бизнес-анализ и выбор сценария для определения основных сценариев с наибольшей интеллектуальной ценностью для предприятия, таких как предиктивное обслуживание, оптимизация энергопотребления, обнаружение аномалий, планирование пути и т. д., требуют тесного сотрудничества между командой ИИ и бизнес-командой для выяснения «места» использования ИИ;
Во-вторых, сбор и очистка данных. Создание высококачественных отраслевых информационных активов является необходимым условием эффективности модели. Особенно в сценариях AIoT источники данных разнообразны (датчики, журналы оборудования, исторические условия работы и т. д.), а также необходимо обрабатывать временные ряды, пропущенные значения, аномалии и другие проблемы.
В-третьих, обучение модели, специфичной для предприятия: на основе общей большой модели отраслевые данные используются для трансферного обучения, точной настройки инструкций и внедрения знаний для создания специализированной модели с отраслевой семантикой и бизнес-логикой.
В-четвертых, разработка и итерация приложений на основе сценариев, инкапсуляция возможностей модели в виде API или интеграция их в бизнес-системы для формирования интеллектуальных приложений, таких как развернутые на периферии интеллектуальные терминалы, интерактивные помощники по эксплуатации и обслуживанию, автоматизированные системы принятия решений и т. д., которые впоследствии могут получать непрерывную обратную связь и выстраивать замкнутый цикл итерации модели.
Стоит отметить, что только путем настройки на основе крупной модели, проверенной рынком и обладающей определенными общими возможностями, мы можем добиться вдвое большего результата, затратив вдвое меньше усилий и избежав «изобретения велосипеда с нуля».
Хотя вертикальные модели стали новой тенденцией в развитии AIoT, на практике они по-прежнему сталкиваются со множеством проблем, которые нельзя игнорировать.
Первая — сложность обучения и настройки модели. Требования к моделям в разных отраслях существенно различаются, и не существует универсального шаблона, который можно было бы скопировать.
Такие сценарии, как промышленность, электроэнергетика, сельское хозяйство и здравоохранение, имеют огромные различия в разреженности данных, доступности меток и определении стандартов аномалий. Предприятиям необходимо создать механизм, который интегрирует графы отраслевых знаний, системы правил и экспертные системы для создания по-настоящему «модели мышления».
Второе — противоречие между эффективностью вывода и вычислительной мощностью периферийных вычислений. Вертикальные модели должны работать на периферийных устройствах, что требует от моделей легкости, малой задержки и высокой надежности. В настоящее время развертывание моделей Transformer на периферийных устройствах по-прежнему сталкивается с нехваткой ресурсов, и необходимо внедрять такие технологии, как сжатие моделей, дистилляция и квантизация.
Вторая — это совместная стратегия общих моделей и вертикальных моделей. Общая модель может служить «базой знаний» для обеспечения возможностей обобщения; вертикальная модель фокусируется на оптимизации сценариев и обеспечивает эффективность принятия решений; В будущем ИИ будет представлять собой структуру «общего + вертикального + многомодального слияния», формируя совместную модель «облачного общего интеллекта + периферийного вертикального интеллекта».
Наконец, существуют проблемы конфиденциальности данных, безопасности и соответствия нормативным требованиям. Данные в сценариях AIoT в основном представляют собой частные активы предприятий, включающие конфиденциальную информацию, такую как производственные секреты, статус устройства и поведение пользователя. Правила также требуют четких границ использования данных. В будущем нам следует разработать механизмы защиты конфиденциальности, которые «сохраняют данные в неподвижном состоянии, но перемещают модели», такие как федеративное обучение и дифференциальная конфиденциальность.
Заключение
В эпоху AIoT 2.0, если компании хотят занять лидирующие позиции в области интеллектуальной трансформации, им следует перейти от «погони за размером модели» к «созданию отраслевого мозга». Это не только выбор технического пути, но и решение о стратегической трансформации.
Тот, кто сможет лучше интегрировать отраслевые знания с технологией ИИ, сможет создавать интеллектуальные приложения, наилучшим образом отвечающие потребностям сценариев.
Тот, кто сможет эффективнее использовать активы бизнес-данных, будет иметь самый умный и надежный мозг в отрасли.
Тот, кто сможет лучше разрушить барьеры между ИТ и ОТ, сможет по-настоящему стимулировать интеллектуальную трансформацию бизнес-процессов.
Ссылки:
Какую пользу приносит популярность DeepSeek в Интернет вещей ? Каковы основные направления применения IoT-LLM? Автор: Чжао Сяофэй, Источник: IoT Think Tank 2.
Периферийный ИИ для роботов, интеллектуальные устройства не за горами, Автор: Паула Руни, Источник: CIO.com
Источник: https://www.iot101.com/news/9825.html