6 сентября в Пекина открылся ежегодный Global AI Chip Summit (GACS 2024). Зал был заполнен посетителями, а количество зрителей прямой трансляции достигло 1,2 миллиона.

Конференция была инициирована и организована Chip East, дочерней компанией Zhiyi Technology, и Zhixingxing, под названием «Создание дороги для чипов в эпоху интеллектуальных вычислений» (Building a Chip Road in the Era of Intelligent Computing). На конференцию было приглашено более 50 гостей из области промышленности ИИ-чипов, чиплетов, RISC-V, интеллектуальных вычислительных кластеров, ИИ-инфраструктуры, чтобы поделиться практической информацией.

Толпы людей внутри и снаружи места проведения мероприятия
Также мероприятие было ознаменовано пятой годовщина создания компании-единорога в области GPGPU (General-purpose computing on graphics processing units, неспециализированные вычисления на графических процессорах) BiRen Technology. На встрече BiRen Technology объявила, что достигла прорыва в основных технологиях в многоядерном смешанном обучении и создала гетерогенное решение для совместного обучения GPU — HGCT. Впервые в отрасли оно может поддерживать 3 или более гетерогенных GPU для обучения одной и той же большой модели.
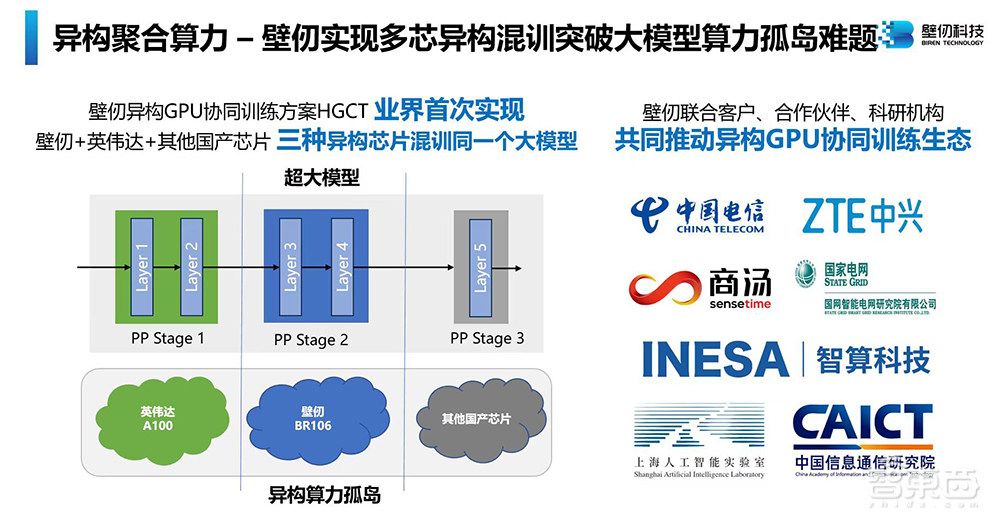
Biren Technology запускает собственное решение для совместного обучения гетерогенных графических процессоров HGCT
Гонг Лунчан, соучредитель и генеральный директор Zhiyi Technology, выступил с речью от лица организатора мероприятия. В этом году Global AI Chip Summit проводится в седьмой раз. Саммит стал самой влиятельной отраслевой конференцией в этой области в Китае и важной площадкой для понимания развития чипов ИИ в стране и за рубежом.

Гонг Лунчан, соучредитель и генеральный директор Zhiyi Technology
Глобальный саммит AI Chip Summit длится два дня. Основная площадка включает церемонию открытия и три основные сессии (архитектура ИИ-чипов, ИИ-чипы для центров обработки данных, Edge ИИ-чипы). В число дополнительных площадок входят Форум по технологиям чиплетов, Форум по технологиям интеллектуальных вычислительных кластеров и Форум инноваций RISC-V.
На церемонии открытия Инь Шойи, профессор Университета Цинхуа и заместитель декана Школы интегральных схем, выступил с программной речью на тему «Дискуссия о пути развития чипов высокой вычислительной мощности: от вычислительной архитектуры к интегрированной архитектуре». Он систематически рассматривает существующие технические проблемы и всесторонне проанализировал пять инновационных технологических направлений: чипы потока данных, интегрированные чипы хранения и вычислений, реконфигурируемые чипы, трехмерные интегрированные чипы и чипы уровня пластины.
В мероприятии примут участие 21 эксперт, предприниматель и руководитель из ведущих университетов, исследовательских институтов и компаний, производящих чипы искусственного интеллекта. Среди них на панельную дискуссию были приглашены представители трех стартапов, занимающихся чипами искусственного интеллекта: BiRen Technology — китайский производитель мощных чипов, Aixin Yuanzhi — производитель чипов ИИ для конечного и периферийного оборудования, и компания Lingchuan Technology — молодой стартап по производству чипов ИИ, основанный полгода назад. Они сосредоточились на обсуждении текущего состояния, новейших практик и передовых направлений индустрии ИИ-чипов.
1. Решение проблем спроса и предложения, связанных с вычислительной мощностью крупномасштабных моделей, и инновационная архитектура для преодоления узких мест в производительности.
Инь Шоуи, профессор Университета Цинхуа и заместитель декана Школы интегральных схем, объяснил трудности с предложением и спросом на вычислительную мощность в эпоху больших моделей: технология микросхем сталкивается с пределом масштабирования — результаты от вложений в увеличение вычислительной мощности становится непредсказуемыми, система сталкивается с узким местом в виде недостаточной пропускной способность связи, что приводит к потере производительности системы.
Возможность решить эти две основные проблемы заключается в совместных инновациях вычислительной архитектуры чипов и интегрированной архитектуры: инновации в вычислительной архитектуре позволяют полностью использовать каждый транзистор и реализовать более высокую вычислительную мощность; инновации в интегрированной архитектуре позволяют масштабам чипов выйти за существующие пределы.
В настоящее время существует пять новых технологических путей разработки чипов высокой вычислительной мощности: чипы потока данных, реконфигурируемые чипы, интегрированные чипы хранения и вычислений, трёхмерные интегрированные чипы и чипы уровня пластины. Ни один из этих путей полностью не опирается на самые передовые производственные процессы, которые помогут открыть новое пространство для китайской индустрии микросхем для повышения вычислительной мощности.

Инь Шоуи, профессор Университета Цинхуа и заместитель декана факультета интегральных схем
AMD создала широкую линейку продуктов в области комплексной инфраструктуры ИИ, охватывающую от серверов центров обработки данных, ПК с искусственным интеллектом до интеллектуальных встраиваемых и периферийных устройств, а также предоставляет ведущее программное обеспечение для ИИ с открытым исходным кодом и открытую экосистему. Платформа процессоров AMD, разработанная на основе передовой архитектуры ZEN4, и ускорители серии MI на основе архитектуры CDNA3 для тренировки и обучения ИИ были приняты на вооружение такими гигантами, как Microsoft.
По словам Ван Хунцяна, старшего директора подразделения искусственного интеллекта AMD, компания также продвигает высокопроизводительную сетевую инфраструктуру (UALink, Ultra Ethernet) в центрах обработки данных, что имеет решающее значение для сетевых структур искусственного интеллекта для поддержки быстрого переключения и чрезвычайно низкой задержки, а также для важно расширить производительность центра обработки данных AI.
AMD собирается выпустить следующее поколение высокопроизводительных компьютеров с искусственным интеллектом. Ее процессор Ryzen AI NPU на базе архитектуры XDNA второго поколения может обеспечить вычислительную мощность 50TOPS и увеличить коэффициент энергоэффективности до 35 раз по сравнению с архитектурой общего назначения. Благодаря стремлению ИИ ПК к конфиденциальности, безопасности и автономности данных, важные рабочие нагрузки ИИ начинают развертываться на ПК. Являясь одним из ведущих мировых поставщиков инфраструктуры искусственного интеллекта, AMD готова работать с клиентами и разработчиками для построения будущего.

Ван Хунцян, старший директор подразделения искусственного интеллекта AMD
С 2015 года компания Qualcomm постоянно совершенствует аппаратное обеспечение NPU, учитывая изменения в сценариях использования приложений искусственного интеллекта. Qualcomm AI Engine, представленный процессором Snapdragon 8 третьего поколения, использует гетерогенную вычислительную архитектуру, объединяющую несколько процессоров, таких как ЦП, графический процессор и NPU. Среди них Qualcomm Hexagon NPU оптимизирует производительность и энергоэффективность за счет большого объема памяти, выделенного источника питания для ускорителей, обновления микроархитектуры и других разработок. Искусственный интеллект имеет множество вариантов использования и различные требования к вычислительной мощности. Поэтому спрос на интеграцию гетерогенных вычислений и процессоров будет существовать в течение длительного времени, что также приведет к ряду улучшений в пиковой производительности, энергоэффективности, стоимости и т. д.
Линейка продуктов Qualcomm охватывает широкий спектр сценариев периферийных приложений, таких как мобильные телефоны, ПК, XR, автомобили и Интернет вещей. Она может помочь разработчикам использовать программные и аппаратные решения Qualcomm для ускорения алгоритмов в различных формах продуктов, что приносит богатство преимуществ для использования искусственного интеллекта на устройствах. Наконец, Ван Вейсин, глава подразделения Qualcomm AI Product Technology China, также объявил, что мобильная платформа Snapdragon следующего поколения, оснащенная новейшим процессором Qualcomm Oryon, будет представлена на саммите Snapdragon, который пройдет с 21 по 23 октября этого года.

Ван Вейсин, руководитель подразделения Qualcomm AI Product Technology в Китае
Ян Юэ, соучредитель и генеральный директор Pingxin Technology, рассказал о процессе развития интегрированных технологий хранения и вычислений. Появление и рост массовых чипов в отрасли тесно связаны с характеристиками текущих вычислительных потребностей. Примерно в 2015 году узкое место в вычислительной архитектуре переместилось со стороны процессора на сторону хранения, особенно с появлением нейронных сетей. В частности, появление нейронных сетей ускорило темпы повышения вычислительной эффективности чипов искусственного интеллекта, поэтому технологии хранения и вычислений привлекли внимание.
Ян Юэ считает, что в эпоху больших моделей возможность интегрированных технологий хранения и вычислений заключается в добавлении вычислений везде, где есть хранилище данных. Благодаря постоянному развитию программного обеспечения в этом году постепенно совершенствовались чипы на стороне устройства, основанные на хранении и вычислениях. В будущем решение проблем с пропускной способностью данных в облаке может стать следующим прорывным приложением для чипов хранения и вычислений.

Ян Юэ, соучредитель и генеральный директор Pingxin Technology
Тан Чжаньхун, технический директор Arctic Xiongxin, сказал, что в области высокопроизводительных вычислений существуют две разные парадигмы проектирования серверов: стандартная серверная архитектура и кастомизируемая серверная архитектура. В стандартная серверная архитектуре Arctic Xiongxin фокусируется на достижении более высокой экономической эффективности за счет соответствующих решений по разделению чипов и компоновке в пределах стандартной ограниченной области; кастомизируемая архитектура сервера предоставляет возможности для интеграции на уровне пластины, уделяя особое внимание интеграции чипов и дизайну системы, а также совместному проектирование серверов и микросхем с целью достижения цели «сервер как чип».
В частности, Тан Чжаньхун подчеркнул, что разные архитектуры чипов имеют разные требования к пропускной способности. Например, в процессах выше 7 нм в сочетании с оптимизацией связи при развертывании часто не требуется высокая плотность полосы пропускания межсоединений, поэтому расширенная компоновка не требуется. 2D-компоновка может удовлетворить требования к производительности и достичь экономически эффективного решения. Также компания Arctic Xiongxin представила экономичный интерфейс для межсоединения чипов, основанный на IP-интерфейсе PB-Link, созданном на базе «Стандарта интерфейса межсоединения чипов» (Chips Interconnect Interface Standard), и начала предлагать лицензии для сторонних компаний.

Технический директор Arctic Xiongxin Тан Чжаньхун
2. Дискуссия: отечественные чипы ИИ расширили возможности генерировать доход, а продукты самого молодого стартапа появились в Kuaishou.
Чжан Гуорен, соучредитель и главный редактор Zhiyi Technology, Дин Юньфан, вице-президент и главный архитектор программного обеспечения для искусственного интеллекта BiRen Technology, Лю Ли, соучредитель и вице-президент Lingchuan Technology, и Лю Цзяньвэй, соучредитель-основатель и вице-президент Aixin Yuanzhi провели дискуссию. Диалог за круглым столом прошел на тему «Консенсус, совместное творчество и взаимовыгодное сотрудничество при внедрении отечественных чипов искусственного интеллекта».

Чжан Гуорен сказал в начале диалога за круглым столом, что шесть шестой саммит AI Chip, инициированный компаниями Zhidongxi, Xindongxi и Zhixingxing, является самой продолжительной профессиональной конференцией в этой области в Китае. В последние годы мы стали свидетелями энергичного развития чипов ИИ и больших моделей, а также появления ряда отечественных «новых сил», производящих чипы.

Чжан Гуорен, соучредитель и главный редактор Zhiyi Technology
Дин Юньфань рассказал, что процессоры большой вычислительной мощности — это наукоемкая, трудоемкая и капиталоемкая отрасль. Компания BiRen Technology, являющаяся производителем чипов с крупнейшим государственным финансированием на рынке, обладает выдающимися талантами. Ее продукты первого поколения производятся серийно, а также выпущено несколько кластеров из тысяч графических процессоров, которые могут независимо генерировать данные. Однако общая ситуация в отечественной отрасли производства микросхем по-прежнему непростая, и все еще существует разрыв между экологическими аспектами и зарубежными странами.
Многие китайские чипы ИИ начали внедряться в центрах обработки данных и интеллектуальных вычислительных центрах. По мнению Дин Юньфаня, продукция NVIDIA не очень эффективна с точки зрения затрат. Пока китайские чипы не смогут обеспечить подобную высокую производительность и экономичность, она будет присутствовать на рынке. В настоящее время появляется все больше новостей о запуске отечественного производства чипов и росте их производительности, поэтому разрыв с Nvidia постепенно будет сокращаться.

Дин Юньфан, вице-президент BiRen Technology и главный архитектор программного обеспечения для ИИ
Лю Цзяньвэй считает, что низкая стоимость является очень важной частью, и компаниям в конечном итоге придется свести баланс, а их инвестиции в инфраструктуру должны быть возвращены. Лю Ли считает, что в будущем в отдельных сегментах рынка, таких как встроенный интеллект и интеллектуальное видео, появление большего числа компаний принесет более высокую ценность, чем обычные продукты, что снизит доходы и прибыль Nvidia.
Lingchuan Technology — один из самых молодых китайских стартапов по производству чипов ИИ. Он был основан в марте этого года и завершил раунд финансирования. Чипы для умной обработки видео, которые в настоящее время продаются, были запущены в работу в сервисе Kuaishou, и на них приходится до 99% нагрузки по обработке видео. Ожидается, что высокопроизводительный чип вывода будет выпущен в начале следующего года.
По мнению Лю Ли, окно рынка ИИ-чипов еще далеко не закрыто. Столкнувшись с преимуществами гигантов в ресурсах, средствах и экологии, стартапам необходимо сфокусироваться на вертикальных рынках и отдельных сегментах. Чипы Lingchuan Technology сочетают в себе интеллектуальную обработку видео и вычислительную мощность для достижения выгоды до 10% на токен по сравнению с NVIDIA H800.

Лю Ли, соучредитель и вице-президент Lingchuan Technology
Компания Aixin Yuanzhi, ориентированная выпуск продукции как для периферийных, так и центральных устройств, добилась выдающихся результатов в увеличении доли рынка. Лю Цзяньвэй считает, что в этих двух сегментах коммерческий эффект будет достигнут быстрее. Он добавил, что производство чипов ИИ в конечном итоге принесет прибыль, но на фактический график роста прибыли будут влиять такие факторы, как затраты на развертывание ИИ, и компаниям следует как можно скорее достичь генерации прибыли и замкнутого цикла. В будущем Aixin Yuanzhi будет изучать сценарии реализации больших моделей на периферийных и центральных устройствах.
Поставки продукции Aixin Yuanzhi в автомобильной сфере очень впечатляют. Лю Цзяньвэй сказал, что это связано с тем, что базовая технология чипов для «Умных городов» и автомобилей схожа. Aixin Yuanzhi накопила обширные технологии в сфере «Умных городов», а затем приступила к массовому производству решений для умного вождения. В то же время ценовая война в автомобильной сфере будет способствовать промышленному разделению труда, что является дополнительным окном возможностей для компании.

Лю Цзяньвэй, соучредитель и вице-президент Aixin Yuanzhi
Что касается того, насколько быстро китайские чипы ИИ могут найти свою рыночную нишу, Лю Цзяньвэй привел в качестве примера разработку Aixin Yuanzhi. В проектах Умных городов практически нет продукции иностранных компаний. В области интеллектуального вождения NVIDIA развивается от 0 до 1 этапа, а этапы с 1 до 100, на котором больше внимания уделяется затратам, — это возможности для внутреннего бизнеса. Дин Юньфан упомянул четыре элемента: гарантия стабильных и надежных поставок, экономическая эффективность, эффективные услуги поддержки, основанные на потребностях клиентов, а также эффективность и простота использования. Лю Ли считает, что китайским компаниям следует глубже погружаться в вертикальные области и создавать более эффективные и оптимизированные решения, чем чипы общего назначения.
Заглядывая в будущее, Лю Цзяньвэй прогнозирует, что в ближайшие 4–5 лет откроются большие возможности для развития как на стороне устройств, так и на стороне облачных сервисов. После того, как стоимость внедрения в отрасли снизится, данные смогут получить большую ценность. Лю Ли считает, что по мере того, как приложения ИИ вступят в бурный период роста, спрос на облачные технологии будет расти. Дин Юньфань сказал, что в Китае по-прежнему не хватает высокопроизводительных вычислительных мощностей, но сотрудничество производственной цепочки может обеспечить устойчивое развитие.
3. Строительство интеллектуальных вычислительных центров находится на подъеме: новые прорывы в области графических процессоров, китайские GPU, китайские TPU выходят на рынок, чиплеты побеждают.
На сессии по созданию чипов для центров обработки данных, состоявшейся во второй половине дня, Ю Минъян, глава Habana China, сообщил, что за последние три года было построено более 50 интеллектуальных вычислительных центров под руководством правительства, и более 60 находятся в стадии планирования и строительства. Строительство интеллектуальных вычислительных центров постепенно смещается от городов первого уровня к городам второго и третьего уровня, а также от государственных ЦОД к корпоративным, также постепенно возрастают требования по снижению затрат и сроку возврата инвестиций.
По его наблюдениям, разработка больших моделей становится все более зрелой, спрос на логические выводы продолжает расти, темпы роста количества самостоятельно разрабатываемых ведущими CSP чипов будут увеличиваться. В будущем в Китае могут вырасти несколько компаний, производящих гетерогенные чипы.
Спрос на обучение крупных моделей за рубежом по-прежнему будет высоким, а спрос на вычислительные мощности для обучения моделей внутри Китая в основном насыщен, в основном услугами по тонкой настройке моделей. Для поддержки будущего развития ИИ ключевую роль будет играть интеграция чиплетов, высокоскоростной памяти большой емкости и частных/общих технологий высокоскоростного соединения.

Ю Минъян, глава Habana China
Чтобы решить проблему разрозненных вычислительных мощностей для больших моделей, Дин Юньфан, вице-президент BiRen Technology и главный архитектор программного обеспечения для искусственного интеллекта, объявил о запуске собственного оригинального решения BiRen для совместного обучения гетерогенных графических процессоров HGCT. Впервые в отрасли поддерживается три или более разнородных графических процессоров для совместного обучения одной и той же большой модели, то есть поддерживается смешанное обучение с графическими процессорами NVIDIA + BiRen + других марок. Эффективность связи превышает 98%. а эффективность сквозного обучения достигает 90~95%.
BiRen работает с клиентами и партнерами над совместным продвижением гетерогенной экосистемы совместного обучения графических процессоров, включая China Telecom, ZTE, SenseTime, Государственный институт интеллектуальных сетевых исследований, Shanghai Intelligent Computing Technology Co., Ltd., Шанхайскую лабораторию искусственного интеллекта, Китайскую академию информационных и коммуникационных технологий и т.д.
Ее продукты были развернуты для коммерческого использования в кластерах графических процессоров Quinka. Компания BiRen разработала комплексное решение для больших моделей, которое объединяет программное и аппаратное обеспечение, оптимизированное для работы гетерогенных моделей и имеющее открытый исходный код. BiRen впервые реализовала автоматическое эластичное расширение и сжатие 3D параллельных задач больших моделей, сохраняя уровень использования кластера почти на 100%, добилась эффекта автоматического восстановления модели из 100 миллиардов параметров в кластере Qianka за 10 минут, обеспечив отсутствие сбоев в течение 4 дней и отсутствие перерывов работы в течение 15 дней.

Дин Юньфан, вице-президент BiRen Technology и главный архитектор программного обеспечения для ИИ
Чжэн Ханьсюнь, соучредитель и технический директор Zhonghao Xinying, сказал, что сегодняшние большие модели ИИ предъявляют требования к вычислительной сложности и вычислительной мощности намного выше, чем когда-либо существовали в истории вычислений, и требуют специализированных чипов, которые лучше справляются с расчетами ИИ. По сравнению с графическим процессором, который изначально был разработан для рендеринга и обработки изображений в реальном времени, TPU в основном предназначен для машинного обучения, моделей глубокого обучения и вычислений на основе нейронных сетей и специально оптимизирован для тензорных операций. Пропускная способность и эффективность обработки архитектуры с одним систолическим массивом были значительно улучшены по сравнению с графическим процессором.
Чип Moment, разработанный компанией Zhonghao Xinying, является первым в Китае высокопроизводительным ИИ-чипом с архитектурой TPU. После всестороннего расчета вычислительной производительности, стоимости и энергопотребления стоимость единицы вычисления составляет всего 50% от стоимости ведущих зарубежных графических процессоров. Чжэн Ханьсюнь считает, что на более поздних стадиях разработки крупномасштабных моделей решающее значение будет иметь наилучшее соотношение затрат и эффективности для кластеров емкостью тысячи и десятки тысяч кард. Прямое высокоскоростное межсоединение между 1024 чипами в чипах Moment позволит превзойти производительность традиционных кластеров на GPU в несколько раз.

Чжэн Ханьсюнь, соучредитель и технический директор Zhonghao Xinying
По словам Стивена Фенга, руководителя отдела открытых продуктов для ускоренных вычислений в Inspur Information, по мере увеличения масштаба параметров больших моделей разработка генеративного ИИ сталкивается с четырьмя основными проблемами: недостаточная масштабируемость кластера, высокое энергопотребление чипов, трудности с развертыванием кластера и низкая надежность системы. Inspur Information всегда была ориентирована прикладной и системно-ориентированный подход, стимулируя развитие генеративного ИИ через систему с открытым кодом.
Что касается открытости аппаратного обеспечения, компания разработала спецификацию OAM (Open Acceleration Module) для содействия разработке передовых вычислительных мощностей и поддержки итеративного ускорения больших моделей и приложений ИИ. Что касается открытости программного обеспечения, с помощью платформы разработки крупных моделей «Metabrain Enterprise Intelligence» EPAI создана платформа поддержки полного процесса разработки приложений для предприятий. С помощью комплексных решений решаются вопросы первичного развертывания больших моделей, процесса комплексной разработки приложений, высоких пороговых значений, сложной многорежимной адаптации и высоких затрат на внедрение, а также ускорение инноваций и внедрение приложений больших моделей на предприятиях.

Стивен Фенг, руководитель подразделения Inspur Information Open Accelerated Computing Products
Компания Qingcheng Jizhi была основана в 2023 году с упором на ИИ-инфраструктуру. Команда была создана на факультете компьютерных наук Университета Цинхуа и накопила более десяти лет опыта в оптимизации мощности интеллектуальных вычислений.
Ши Тяньхуэй, соучредитель Qingcheng Jizhi, поделился, что китайские высокопроизводительные вычислительные системы сталкиваются с такими проблемами, как трудности с восстановлением после сбоев и низкая производительность, что требует взаимодействия 10 основных базовых программных систем. Qingcheng Jizhi располагает продуктами собственной разработки для решения более чем половины этих задач.
В настоящее время Qingcheng Jizhi освоила накопление полностековых технологий от компилятора нижнего уровня до системы параллельных вычислений верхнего уровня, достигнув полного охвата экосистемы больших моделей, выполнила несколько оптимизаций производительности китайских чипов и больших моделей, что привело к значительному росту эффективности вычислений. Среди них система обучения больших моделей «Bagua», разработанная для сверхкрупных кластеров, которая быть расширена до масштаба 100 000 серверов и использоваться для обучения моделей со 174 триллионами параметров.

Ши Тяньхуэй, соучредитель Qingcheng Jizhi
Хуан Сяобо, директор по технологическому маркетингу компании Xinhe Semiconductor, заявил, что спрос на вычислительную мощность увеличился в 60 000 раз за последние 20 лет и может вырасти в 100 000 раз в ближайшие 10 лет. Пропускная способность систем хранения данных и межсетевых соединений стала основными узкими местами в развитии. Интегрированные системы чиплетов стали важным направлением для прорывов в преодолении ограничений передовых процессов и повышения производительности высокопроизводительных вычислений в эпоху после Мура. Они широко использовались в чипах большой вычислительной мощности ИИ и чипах сетевой коммутации кластеров ИИ-вычислений.
В связи с этим Xinhe Semiconductor предоставляет универсальную платформу мультифизического моделирования EDA для проектирования и разработки интегрированных систем чиплетов. Платформа поддерживает параметрическое моделирование структур межсоединений при проектировании основных процессов, а ее возможности моделирования в 10 раз быстрее, чем у других платформ, при потребности памяти в 20 раз меньше, а также имеет встроенный анализ протокола HBM/UCIe для повышения эффективности моделирования. Она используется многими ведущими производителями ИИ-чипов в Китае и за рубежом, чтобы ускорить внедрение интегрированных системных продуктов на базе чиплетов большой вычислительной мощности.
Хуан Сяобо, директор по технологическому маркетингу Xinhe Semiconductor
Во время обучения больших моделей накладные расходы сетевой инфраструктуры составляют 30%, что подчеркивает важность производительности сети. По словам Чжу Цзюньдуна, соучредителя и вице-президента по продуктам и решениям KiwiMoore, сеть стала узким местом в производительности интеллектуальных вычислений. Для построения сети ИИ требуется интеграция трех сетей, а именно межсетевого взаимодействия между кластерными сетями, межсетевого взаимодействия внутри шкафов и взаимодействие между чипами.
Кластеры больших интеллектуальных вычислений требуют высокопроизводительного соединения, и модернизация RDMA и чиплетов стали ключевыми технологиями. Для оптимизации RDMA и ускорения сети предназначена серия чиплетов KiwiMoore NDSA на базе программируемой многоядерной потоковой архитектуре и использования высокопроизводительного механизма обработки данных для достижения высокопроизводительного потока данных и гибкого ускорения данных. Чиплет GPU Link «NDSA-G2G», впервые разработанный KiwiMoore, основан на инфраструктуре Ethernet и благодаря высокопроизводительному механизму обработки данных и технологии интерфейса D2D позволяет достичь высокой пропускной способности масштабируемой сети на уровне терабайт, а его производительность сравнима с эталоном глобальной технологии межсетевых соединений.

Чжу Цзюньдун, соучредитель KiwiMoore и вице-президент по продуктам и решениям
Alphawave — компания, предоставляющая решения по проектированию IP, чиплетов и ASIC для высокопроизводительных вычислений, ИИ и высокоскоростных сетевых приложений. Го Давэй, ее старший бизнес-директор в Азиатско-Тихоокеанском регионе, поделился, что IP-продукты Alphawave имеют коэффициент ошибок по битам, который на 2 порядка ниже, чем у конкурирующих продуктов, могут помочь в интеграции и проверке данных и глубоко интегрированы с экосистемой Arm. Они также могут обеспечить поддержку полного жизненного цикла SoC клиентов.
Что касается чиплетов, Alphawave помогает клиентам сократить цикл, снизить затраты, повысить производительность и скорость итераций. Сейчас компания создала первый в отрасли чиплет с многопротокольным подключением ввода-вывода, который был запущен в производство в этом году. Что касается индивидуальных чипов, Alphawave в основном фокусируется на процессах ниже 7 нм и может выполнить весь процесс от спецификации до вывода на ленту в соответствии с потребностями клиентов. В настоящее время компания осуществила более 375 успешных операций по выводу на ленту с DPPM менее чем 25.
Го Давэй, старший коммерческий директор Alphawave в Азиатско-Тихоокеанском регионе
Вывод: возможности ИИ в сфере вторичной обработки данных растут, и чипы ИИ открывают исторические возможности.
На пути к решению основных вопросов общего ИИ формы алгоритмов ИИ продолжают меняться, и чипы ИИ меняются вместе с ними. Когда древний песок встречается с будущим машинным интеллектом, технологии и инженерная мудрость сливаются и сталкиваются, чипы ИИ с продуманным дизайном входят в вычислительные кластеры и проникают в тысячи домов, поддерживая эволюцию жизни кремния.
От интеллектуальных вычислительных центров и интеллектуального вождения до компьютеров с ИИ, мобильных телефонов с ИИ и нового оборудования с ИИ — тенденция развития нисходящего интеллекта принесла новую волну исторических возможностей для чипов ИИ, работающих в разных областях. Быстро развивающиеся алгоритмы и приложения генеративного ИИ продолжают решать новые проблемы вычислительной мощности. Технологические инновации и рыночный спрос одновременно способствуют расширению рынка ИИ-чипов и диверсификации конкурентной среды ИИ-чипов.
В рамках Глобального саммита AI Chip Summit 2024 была представлена обширная информация: на главной площадке прошли специальные сессии, посвященная инновациям в архитектуре ИИ-чипов и периферийным/конечным ИИ-чипам, а также анонсированы два важнейших перечня — «2024 China Top 20 Intelligent Computing Cluster Solution Companies» и «2024 China Top 10 AI Chip Emerging Companies», на дополнительной площадке прошли Форум по технологиям интеллектуальных вычислительных кластеров и Китайский форум инноваций в области вычислительных чипов RISC-V.
Источник: https://zhidx.com/p/442505.html